Pour qu'il y ait correspondance entre l'information du polynucléotide et celle du polypeptide, il y a un code : le code génétique.
Les caractéristiques générales du code génétique peuvent être énumérées comme suit :
Le code génétique est composé de triplets, et est dépourvu de ponctuation interne (Crick & Brenner,).
Il "a été déchiffré grâce à l'utilisation de" systèmes de traduction à cellules ouvertes "(Nirenberg & Matthaei, 1961; Nirenberg & Leder, 1964; Korana, 1964).
C'est très dégénéré (synonymes).
L'organisation de la table de codes n'est pas fortuite.
Des triplés "non-sens".
Le code génétique est "standard", mais pas "universel".
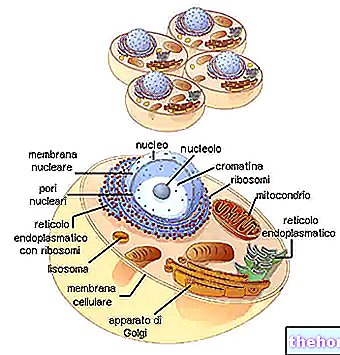
En regardant le tableau du code génétique, il faut se rappeler qu'il s'agit de la traduction de "ARNm en polypeptide, pour lequel les bases nucléotidiques impliquées sont A, U, G, C. La biosynthèse d'une chaîne polypeptidique est la traduction de la séquence nucléotidique en séquence acide aminé.

Chaque triplet de base de l'ARNm, appelé codon, a la première base dans la colonne de gauche, la deuxième dans la rangée du haut, la troisième dans la colonne de droite. Prenons par exemple le tryptophane (c'est-à-dire Try) et nous voyons que le codon correspondant va être, dans l'ordre, UGG. En fait, la première base, U, comprend toute la rangée de cases en haut ; en cela, G identifie la case la plus à droite et la quatrième ligne de la case elle-même, où l'on trouve écrit Try. De même, pour synthétiser le tétrapeptide Leucine-Alanine-Arginine-Serína (symboles Leu-Ala-Arg-Ser), nous pouvons trouver les codons UUA-AUC-AGA-UCA dans le code.

À ce stade, cependant, il convient de noter que tous les acides aminés de notre tétrapeptide sont codés (contrairement au tryptophane) par plus d'un codon. Ce n'est pas un hasard si dans l'exemple qui vient d'être rapporté nous avons choisi les codons indiqués, nous aurions pu coder le même tripeptide avec une séquence d'ARNm différente, telle que CUC-GCC-CGG-UCC.
Initialement, le fait qu'un seul acide aminé corresponde à plus d'un triplet s'est vu attribuer un sens d'aléatoire, également exprimé dans le choix du terme de dégénérescence du code, utilisé pour définir le phénomène de synonymie. D'autre part, certaines données suggèrent que la disponibilité de synonymes se rapportant à une stabilité différente de l'information génétique n'est pas du tout accidentelle.Cela semble être confirmé également par la découverte d'une valeur différente du rapport A + T / G + C aux différents stades de l'évolution. Par exemple, chez les procaryotes, où le besoin de variabilité n'est pas satisfait par les règles du mendélisme et du néo-mendélisme, le rapport A + T / G + C a tendance à augmenter. possibilités de variabilité aléatoires dues à une mutation génétique.
Chez les eucaryotes, en particulier dans les cellules multicellulaires, dans lesquelles il est nécessaire que les cellules d'un même organisme conservent toutes le même patrimoine héréditaire, le rapport A+T/G+C dans l'ADN a tendance à diminuer, diminuant les possibilités de mutations génétiques somatiques .
L'existence de codons synonymes dans le code génétique pose le problème, déjà évoqué, de la multiplicité ou non des anticodons dans le RNAt.
Il est certain qu'il existe au moins un ARNt pour chaque acide aminé, mais il n'est pas également certain qu'un seul ARNt puisse se lier à un seul codon, ou puisse reconnaître indifféremment des synonymes (surtout lorsque ceux-ci ne diffèrent que pour la troisième base).
Nous pouvons conclure qu'il existe en moyenne trois codons synonymes pour chaque acide aminé, tandis que les anticodons sont au moins un et pas plus de trois.
En rappelant que les gènes sont conçus comme des segments uniques de très longues séquences polynucléotidiques d'ADN, il est clair que le début et la fin du gène unique doivent nécessairement être contenus dans la mémoire.
BIOSYNTHESE DES PROTEINES
Dans différentes parties de l'ADN, il y a l'ouverture de la double chaîne et la synthèse des différents types d'ARN.
Lors de l'étape de chargement, les ARNt se fixent sur les acides aminés (préalablement activés par l'ATP et par l'enzyme spécifique). La "machinerie" biosynthétique est incapable de "corriger" les ARNt mal chargés.
L'ARNr se scinde alors en deux sous-unités et, en se liant aux protéines ribosomiques, donne lieu à l'assemblage des ribosomes.
L'ARNm, en passant par le cytoplasme, se lie aux ribosomes, formant le polysome.Chaque ribosome, circulant sur le messager, héberge progressivement l'ARNt complémentaire des codons relatifs, prenant les acides aminés et les liant à la chaîne polypeptidique en formation.
L'ARNt relativement stable rentre dans la circulation. Les ribosomes sont également réutilisés, libérant le polypeptide déjà assemblé.
Le messager, moins stable car tout monocaténaire, est clivé (par la ribonucléase) en les ribonucléotides constitutifs.
Le cycle se poursuit ainsi en synthétisant les uns après les autres les polypeptides sur les ARN messagers fournis par la transcription.